
How to Improve Your Website’s Technical SEO

Image source: Getty Images
Technical SEO requires both marketing and development skills, but you can accomplish a lot without being a programmer. Let’s go through the steps.
When you buy a new car, you only need to press a button to turn it on. If it breaks, you take it to a garage, and they fix it.
With website repair, it’s not quite so simple, because you can solve a problem in many ways. And a site can work perfectly fine for users and be bad for SEO. That’s why we need to go under the hood of your website and look at some of its tech aspects.
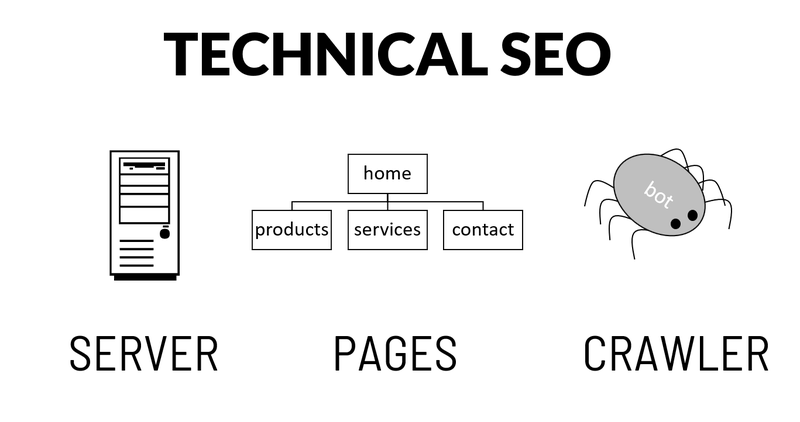
Technical SEO addresses server-related, page-related, and crawler issues. Image source: Author
Overview: What is technical SEO?
Technical SEO refers to optimizing your site architecture for search engines, so they can optimally index and score your content. The architecture pillar is the foundation of your SEO and often the first step in any SEO project.
It sounds geeky and complicated, but it isn’t rocket science. But to meet all the SEO requirements, you may have to get your hands dirty or call in your webmaster during the process.
What comprises technical SEO?
Technical SEO comprises three areas: server-related optimizations, page-related optimizations, and crawl-related issues. In the following, you will find a technical SEO checklist including essential elements to optimize for a small site.
1. Server-related optimizations
A search engine’s main objective is to deliver a great user experience. They optimize their algorithms to send users to great sites that answer their questions. You want the same for your users, so you have the same objective. We’ll look at the following server-related settings:
- Domain name and server settings
- Secure server settings
- Primary domain name configuration
2. Page-related optimizations
Your site is hosted on the server and contains pages. The second section we are going to look at for technical SEO is composed of issues related to the pages on your site:
- URL optimizations
- Language settings
- Canonical settings
- Navigation menus
- Structured data
3. Crawl-related issues
When server and page issues are corrected, search engine crawlers may still run into obstacles. The third section we look at is related to crawling the site:
- Robots.txt instructions
- Redirections
- Broken links
- Page load speed
How to improve your website’s technical SEO
The most efficient way to optimize SEO website architecture is to use an SEO tool called a site crawler, or a “spider,” which moves through the web from link to link. An SEO spider can simulate the way search engines crawl. But first, we have some preparation work to handle.
1. Fix domain name and server settings
Before we can crawl, we need to define and delimit the scope by adjusting server settings. If your site is on a subdomain of a provider (for example, WordPress, Wix, or Shopify) and you don’t have your own domain name, this is the time to get one.
Also, if you haven’t configured a secure server certificate, known as an SSL (secure sockets layer), do that too. Search engines care about the safety and reliability of your website. They favor secure sites. Both domain names and SSL certificates are low cost and high value for your SEO.
You need to decide what version of your domain name you want to use. Many people use www in front of their domain name, which simply means “world wide web.” Or you can choose to use the shorter version without the www, simply domain.com.
Redirect searches from the version you are not using to the one you are, which we call the primary domain. In this way, you can avoid duplicate content and send consistent signals to both users and search engine crawlers.
The same goes for the secure version of your website. Make sure you are redirecting the http version to the https version of your primary domain name.
2. Verify robots.txt settings
Make this small check to verify your domain is crawlable. Type this URL into your browser:
yourdomain.com/robots.txt
If the file you see uses the word disallow, then you’re probably blocking crawler access to parts of your site, or maybe all of it. Check with the site developer to understand why they’re doing this.
The robots.txt file is a commonly accepted protocol for regulating crawler access to websites. It’s a text file placed at the root of your domain, and it instructs crawlers on what they are allowed to access.
Robots.txt is mainly used to prevent access to certain pages or entire web servers, but by default, everything on your website is accessible to everybody who knows the URL.
The file provides primarily two types of information: user agent information and allow or disallow statements. A user agent is the name of the crawler, such as Googlebot, Bingbot, Baiduspider, or Yandex Bot, but most often you will simply see a star symbol, *, meaning that the directive applies to all crawlers.
You can disallow spider access to sensitive or duplicate information on your website. The disallow directive is also extensively used when a site is under development. Sometimes developers forget to remove it when the site goes live. Make sure you only disallow pages or directories of your site which really shouldn’t be indexed by search engines.
3. Check for duplicates and useless pages
Now let’s do a sanity check and a cleanup of your site’s indexation. Go to Google and type the following command: site:yourdomain.com. Google will show you all the pages which have been crawled and indexed from your site.
If your site doesn’t have many pages, scroll through the list and note the URLs which are inconsistent. Look for the following:
- Mentions from Google saying that certain pages are similar and therefore not shown in the results
- Pages which shouldn’t show because they bring no value to users: admin pages, pagination
- Several pages with essentially the same title and content
If you aren’t sure if a page is useful or not, check your analytics software under landing pages, to see if the pages receive any visitors at all. If it doesn’t look right and generates no traffic, it may be best to remove it and let other pages surface instead.
If you have many instances of the above, or the results embarrass you, remove them. In many cases, search engines are good judges of what should rank and what shouldn’t, so don’t spend too much time on this.
Use the following methods to remove pages from the index but keep them on the site.
The canonical tag
For duplicates and near-duplicates, use the canonical tag on the duplicate pages to indicate they are essentially the same, and the other page should be indexed.
Insert this line in the <head> section of the page:
<link rel=“canonical”href=“https://yourdomain.com/main-page-url/” />
If you are using a CMS, canonical tags can often be coded into the site and generated automatically.
The noindex tag
For pages that are not duplicates but shouldn’t appear in the index, use the noindex tag to remove them. It’s a meta tag that goes into the <head> section of the page:
<meta name=”robots” content=”noindex” />
The URL removal tool
Canonical tags and noindex tags are respected by all search engines. Each of them also has various options in their webmaster tools. In Google Search Console, it’s possible to remove pages from the index. Removal is temporary while the other techniques are taking effect.
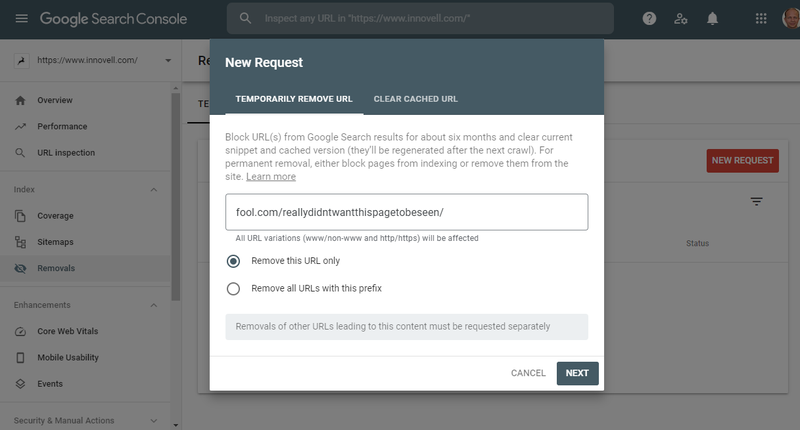
You can quickly remove URLs from Google’s index with the removal tool, but this method is temporary. Image source: Author
The robots.txt file
Be careful using the disallow command in the robots.txt file. This will only tell the crawler it can’t visit the page and not to remove it from the index. Use it once you have cleared all incriminating URLs from the index.
4. Crawl your site like a search engine
For the remainder of this technical SEO run-through, the most efficient next step is to use an SEO tool to crawl your website via the primary domain you configured. This will also help address page-related issues.
In the following, we use Screaming Frog, site crawl software that is free for up to 500 URLs. Ideally, you will have cleaned your site with URL removals via canonical and noindex tags in step 3 before you crawl your site, but it isn’t mandatory.
Screaming Frog is site crawler software, free to use for up to 500 URLs. Image source: Author
5. Verify the scope and depth of crawl
Your first crawl check is to verify that all your pages are being indexed. After the crawl, the spider will show how many pages it found and how deep it crawled. Internal linking can help crawlers access all your pages more easily. Make sure you have links pointing to all your pages and mark as favorites the most important pages, especially from the home page.
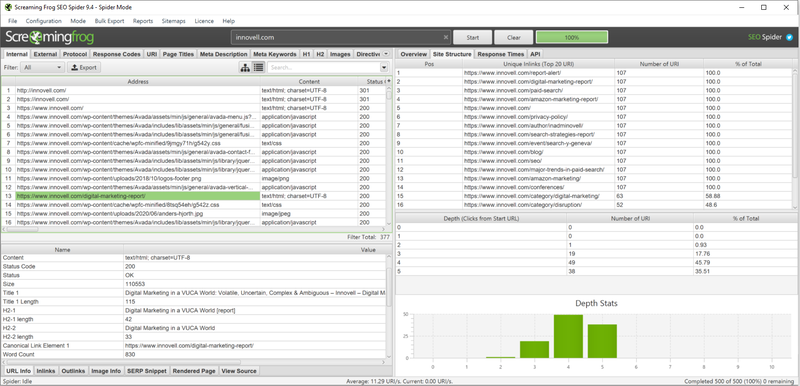
If you discover discrepancies between the number of pages crawled and the number of pages on your site, figure out why. Image source: Author
You can compare the number of site pages to the number found in Google to check for consistency. If your entire site is not indexed, you have internal linking or site map problems. If too many pages are indexed, you may need to narrow the scope via robots.txt, canonical tags, or noindex tags. All good? Let’s move to the next step.
6. Correct broken links and redirections
Now that we’ve defined the scope of the crawl, we can correct errors and imperfections. The first error type is broken links. In principle, you shouldn’t have any if your site is managed with a Content Management System (CMS). Broken links are links pointing to a page that no longer exists. When a user or crawler clicks on the link, they end up on a “404” page, a server error code.
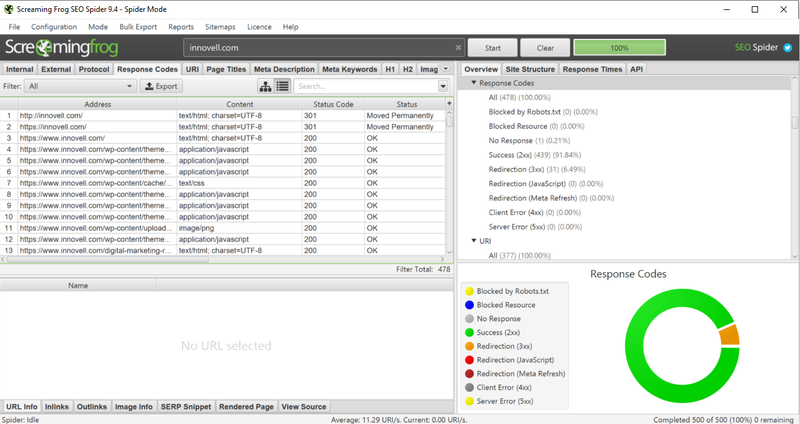
You can see the response codes generated during a site crawl with SEO tools. Image source: Author
We assume you don’t have any “500” error codes, critical site errors that need to be fixed by the site developer.
Next, we look at redirections. Redirections slow down users and crawlers. They are a sign of sloppy web development or temporary fixes. It’s fine to have a limited number of “301” server codes, meaning “Page permanently moved.” Pages with “404” codes are broken links and should be corrected.
7. Create title and meta information
SEO crawlers will identify a number of other issues, but many of them are outside the scope of technical SEO. This is the case for “titles,” “meta descriptions,” “meta keywords,” and “alt” tags. These are all part of your on-page SEO. You can address them later since they require a lot of editorial work related to the content rather than the structure of the site.
For the technical aspect of the site, identify any automated titles or descriptions that can be created by your CMS, but this requires some programming.
Another issue you may need to address is the site’s structured data, the additional information you can insert into pages to pass on to search engines. Again, most CMSes will incorporate some structured data, and for a small site, it may not make much of a difference.
8. Optimize page load speed
The final crawl issue you should look at is page load speed. The spider will identify slow pages, often caused by heavy images or javascripts. Page speed is something search engines increasingly take into account for ranking purposes because they want end users to have an optimal experience.
Google has developed a tool called PageSpeed Insights which tests your site speed and makes recommendations to speed it up.
9. Verify your corrections: Recrawl, resubmit, and check for indexation
Once you have made major changes based on obstacles or imperfections you encountered in this technical SEO run-through, you should recrawl your site to check that corrections were implemented correctly:
- Redirection of non-www to www
- Redirection of http to https
- Noindex and canonical tags
- Broken links and redirections
- Titles and descriptions
- Response times
If everything looks good, you’ll want the site to be indexed by search engines. This will happen automatically if you have a little patience, but if you are in a hurry, you can resubmit important URLs.
Finally, after everything has been crawled and indexed, you should be able to see the updated pages in search engine results.
You can also look at the coverage section of Google Search Console to find details about which pages were crawled and which were indexed.
3 best practices when improving your technical SEO
Technical SEO can be mysterious, and it requires a lot of patience. Remember, this is the foundation for your SEO performance. Let’s look at a few things to keep in mind.
1. Don’t focus on quick wins
It’s common SEO practice to focus on quick wins: highest impact with lowest effort. This approach may be useful for prioritizing technical SEO tasks for larger sites, but it’s not the best way to approach a technical SEO project for a small site. You need to focus on the long term and get your technical foundation right.
2. Invest a little money
To improve your SEO, you may need to invest a little money. Buy a domain name if you don’t have one, buy a secure server certificate, use a paid SEO tool, or call in a developer or webmaster. These are probably marginal investments for a business, so you shouldn’t hesitate.
3. Ask for assistance when you’re blocked
In technical SEO, it’s best not to improvise or test and learn. Whenever you are blocked, ask for help. Twitter is full of wonderful and helpful SEO advice, and so are the WebmasterWorld forums. Even Google offers webmaster office hours sessions.
Fix your SEO architecture once and for all
We’ve covered the essential parts of technical SEO improvements you can carry out on your site. SEO architecture is one of the three pillars of SEO. It’s the foundation of your SEO performance, and you can fix it once and for all.
An optimized architecture will benefit all the work you do in the other pillars: all the new content you create and all the backlinks you generate. It can be challenging and take time to get it all right, so get started right away. It’s the best thing you can do, and it pays off in the long run.